
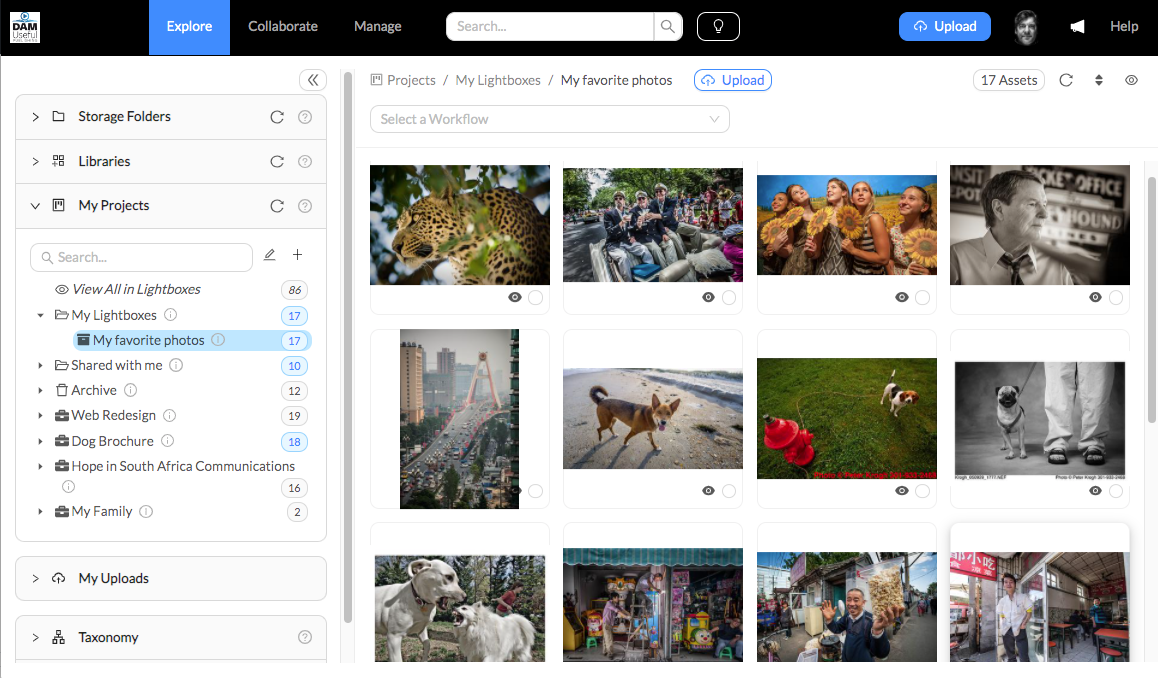
Introducing the next generation of DAM software.
This blog has been quiet, but that’s not because I have been slacking off. For the last year or so, I have been hard at work bringing a new vision
This blog has been quiet, but that’s not because I have been slacking off. For the last year or so, I have been hard at work bringing a new vision

I use the term “object” a lot in The DAM Book 3.0 when I’m referring to digital media. It’s a pretty common word to hear in the software development, museum

PLEASE NOTE: To guaranteed you get the discount, please go to DAMUSEFUL.COM instead of using the BUY buttons on this site! Well, it looks like it’s probably going to be

Editor’s Note: Since I’ve turned Facebook comments off, I’m experimenting with turning them on directly in the blog. Feel free to ask any questions you may have about this subject
This post is adapted from The DAM Book 3.0. In this post, I outline the structural approaches for media management and how they are changing in the cloud/mobile era. Back
We’ve created an index for The DAM Book 3.0. While this was not terribly necessary for electronic versions of the book, it’s quite helpful for the print version (at the
This post is adapted from The DAM Book 3.0. In that book, I describe the ways that connectivity is changing the way we use visual images. In this post, I outline

It is with great pleasure that we can announce the release of the full digital version of The DAM Book 3.0. In the nine years since the last version was
Dateline – Athens, Georgia – We’ve released the next set of chapters for The DAM Book 3.0, adding 325 more pages to the initial Chapter 1 release, for a total of

We are pleased to announce that The DAM Book 3.0 is now available for pre-order! As with our previous books, you can pre-order the book for at a discount. Here