

Black Friday deals from DAM Useful
As is our tradition, we’ll be offering special Black Friday/Cyber Monday deals on all our publications. Get 50% off any of my books, whether electronic or paper. (Note: The discount
As is our tradition, we’ll be offering special Black Friday/Cyber Monday deals on all our publications. Get 50% off any of my books, whether electronic or paper. (Note: The discount

I’ve just finished a production run of PS-4 camera scanning rigs and put them up on our store. If you are looking for an easy way to set up your

We have created a self-serve signup for TV3 trial accounts. Simply click the Show me button and then hit the Start a Free Trial button. No credit card needed.

Civil War Photo Sleuth I moderated a presentation by Vikram Mohanty about the very cool crowdsourcing platform, Civil War Photo Sleuth. They are working at the intersection of crowdsource, machine

In the book Digitizing Your Photos, I outline a method to convert negatives using Lightroom’s curves. I’ve been very happy with the B&W conversions I get, and moderately happy with

Just in time for the holidays, give yourself the gift of a great slide/35mm film copy system. I have six freshly modified PS4 units ready to go, along with four

On November 5, TV3 became the first DAM application in the world to support the new IPTC Alternative Text and Extended Description metadata fields. These fields are designed to assist
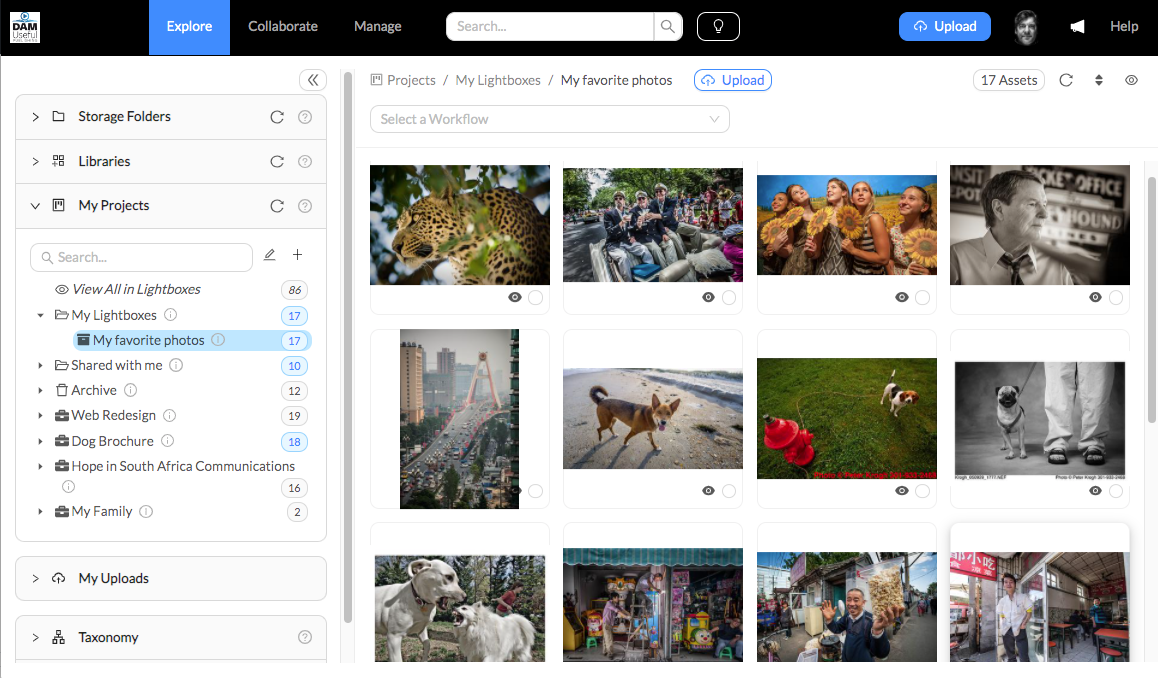
This blog has been quiet, but that’s not because I have been slacking off. For the last year or so, I have been hard at work bringing a new vision
When evaluating the capabilities of an application to read metadata, it’s useful to have a test file that has a lot of metadata filled out. This can tell you which
New article on Petapixel outlines the benefits of Lightroom preview rebuild. Improved speed, saved space and integrity checking.