

Using Google Cloud Vision for OCR
Editor’s Note: This post combines a couple threads I’ve been writing about. I’ll provide some real-world methods for converting visible text to searchable metadata as discussed in Digitizing Your Photos.
Editor’s Note: This post combines a couple threads I’ve been writing about. I’ll provide some real-world methods for converting visible text to searchable metadata as discussed in Digitizing Your Photos.
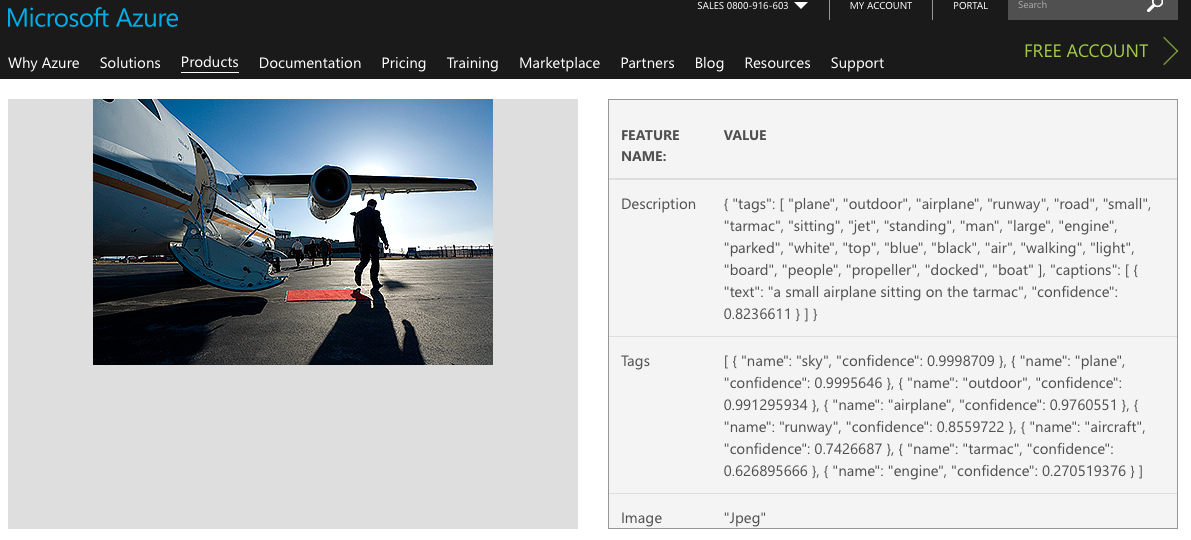
This post is adapted from the forthcoming The DAM Book3. There is a lot of hype and hazy discussion about the future of AI, but it’s often very loosely defined.

This post is adapted from the forthcoming The DAM Book3. There is a lot of hype and hazy discussion about the future of AI, but it’s often very loosely defined.

In my SXSW panel this year, Ramesh Jain and Anna Dickson and I delved into the implications of Artificial Intelligence (AI) becoming a commodity, which will be a commonplace reality