

Editor’s Note: This post combines a couple threads I’ve been writing about. I’ll provide some real-world methods for converting visible text to searchable metadata as discussed in Digitizing Your Photos. In the course of this, I’ll also be fleshing out real-world workflow for Computational Tagging as discussed in The DAM Book 3 Sneak Peeks.
In the book Digitizing Your Photos, I made the case for digitizing textual documents as part of any scanning project. This includes newspaper clippings, invitations, yearbooks and other memorabilia. These items can provide important context for your image archive and the people and events that are pictured.
Ideally, you’ll want to change the visible text into searchable metadata. Instead of typing it out, you can use Optical Character Recognition (OCR) to automate the process. OCR is one of the earliest Machine Learning technologies, and it’s common to find in scanners, fax machines and in PDF software. But there have not been easy ways to automatically convert OCR text to searchable image metadata.
In Digitizing Your Photos, I show how you can manually run images through Machine Learning services and convert any text in the image into metadata through cut-and-paste. And I promised to post new methods for automating this process as I found them. Here’s the first entry in that series.
The Any Vision Lightroom Plugin
I’ve been testing a Lightroom plugin that automates the process of reading visible text in an image and pasting it into a metadata field. Any Vision from developer John Ellis uses Google’s Cloud Vision service to tag your images for several types of information, including visible text. You can tell Any Vision where you want the text to be written, choosing between one of four fields. as shown below.
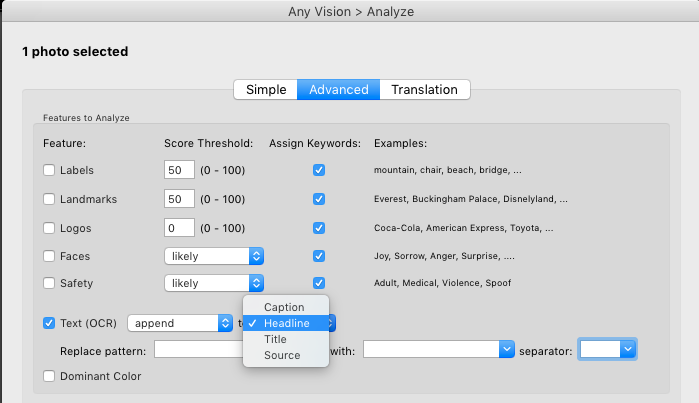
Here is part of the Any Vision interface, with only OCR selected. As you can see, you have the ability to target any found text to either the Caption, Headline, Title or Source filed. I have opted to use the Headline field myself, since I don’t use it for anything else.
Results
Here are my findings, in brief:
- Text that appears in real-life photos (as opposed to copies of textual documents) might be readable, but the results seem a lot less useful.
- Google does a very good job reading text on many typewritten or typeset documents. If you have scanned clippings or a scrapbook, yearbook or other typeset documents, standard fonts seem to be translated reasonably well.
- Google mostly did a poor job of organizing columns of text. It simply read across the columns as though they were one long line of non-sensical text. Microsoft Cognitive Services does a better job, but I’m not aware of an easy way to bring this into image metadata.
- Handwriting is typically ignored.
- For some reason, the translate function did not work for me. I was scanning some Danish newspapers and the text was transcribed but not translated. I will test this further.
Examples
(Click on images to see a larger version)
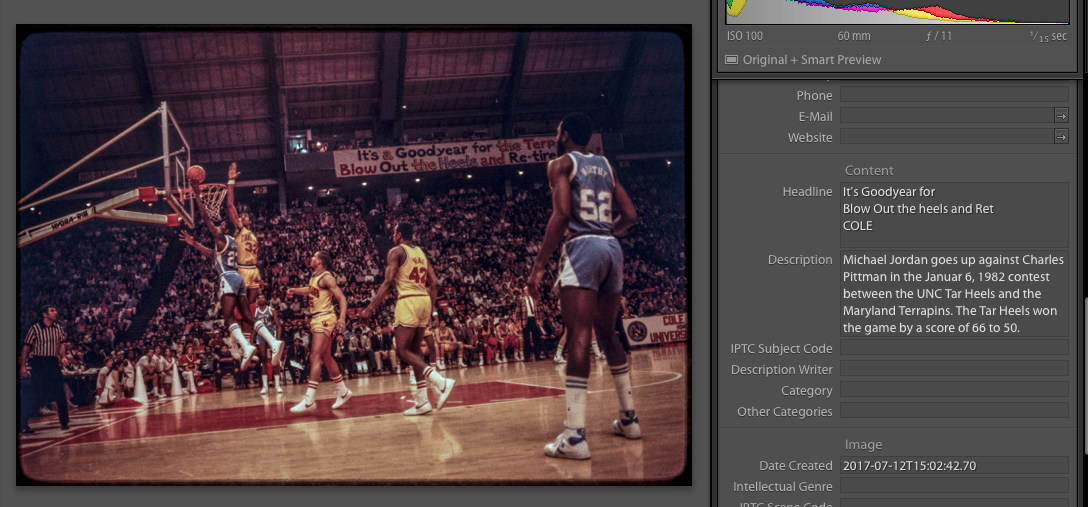
Let’s start with an image that shows why I’m targeting the Headline field rather than the caption field. This image by Paul H. J. Krogh already has a caption, and adding a bunch of junk to it would not be helping anybody.
You can also see that the sign in the background is partially recognized, but lettering in red is not seen and player numbers are ignored even though they are easily readable.
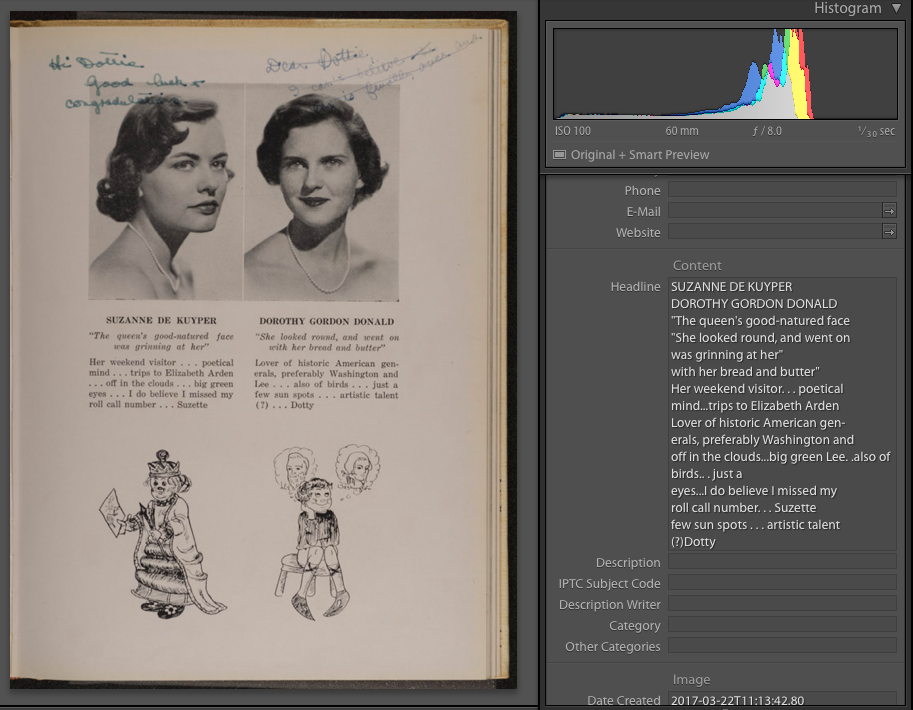
In the example below, from my mother’s Hollins College yearbook, you can see that the text is read straight across, creating a bit of nonsense. However, since the text is searchable, this would still make it easy to find individual names or unbroken phrases in a search of the archive.
You can also see that the handwriting on the page is not picked up at all.
In the next example, you can see that Google was able to see the boxes of text, changes of font and use of underline to hep parse text more properly. 
And in this last example you can see that Google is having a terrible time with the gothic font in this certificate, only picking out a small fraction of letters properly. 
The Bottom Line
If you have a collection of scanned articles or other scanned textual documents in Lightroom, this is a great way to make visible text searchable. While Google is not the best OCR, thanks to Any Vision, it’s the easiest way I know of to add the text to image metadata automatically.
AnyVision is pretty geeky to install and use, but the developer has laid out very clear instructions for getting it up and running and for signing up for your Google Cloud Vision account. Read all about it here.
Cost
Google’s Cloud Vision is very inexpensive – it’s priced at $.0015/per image (which works out to $1.50 for 1000 images.) Google will currently give you a $300 credit when you create an account, so you can test this very thoroughly before you run up much of a bill.
Watch for another upcoming post where I outline some of the other uses of Any Vision‘s tagging tools.