
This post is adapted from the forthcoming The DAM Book3.
There is a lot of hype and hazy discussion about the future of AI, but it’s often very loosely defined. In a previous blog post, I made the case for lumping a lot of this into a category I’m calling Computational Tagging. In the second post, I made a distinction between Artificial Intelligence, Machine learning, and Deep Learning, In this post, I’ll outline a number of the capabilities that fall under the rubric of Computational Tagging.
What can computers tag for?
The subject matter will be an ever growing list, and in large part will be determined by the willingness of people and companies to pay for these services. but as of this writing, the following categories are becoming pretty common.
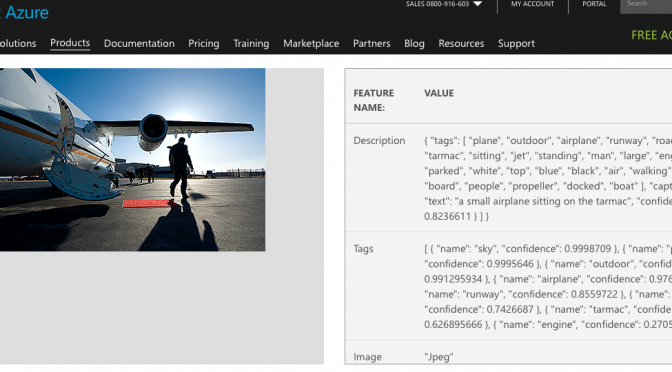
- Objects shown – This was one of the first goals of AI services, and has come a long way. Most computational tagging services can identify objects, landscapes and other generically identifiable elements.
- People and activities shown – AI services can usually identify if a person appears in a photo, although they may not know who it is unless it is a celebrity or unless the service has been trained for that particular person. Many activities can now be recognized by AI services, running the gamut from sports to work to leisure.
- Specific People – Some services can be trained to recognize specific people in your library. Face tagging is part of most consumer-level services and is also found in some trainable enterprise services.
- Species shown – Not long ago, it was hard for Artificial Intelligence to tell the difference between a cat and a dog. Now it’s common for some services to be able to tell you which breed of cat or dog (as well as many other animals and plants.) This is a natural fit for a machine learning project, since plants and animals are well-categorized training set and there are a lot of apparent use cases.
- Adult content – Many computational tagging services can identify adult content, which is quite useful for automatic filtering. Of course, notions of what constitutes adult content varies greatly by culture.
- Readable text – Optical Character Recognition has been a staple of AI services since the very beginning. This is now being extended to handwriting recognition.
- Natural Language Processing – It’s one thing to be able to read text, it’s another thing to understand its meaning. Natural Language Processing (NLP) is the study of the way that we use language. NLP allows us to understand slang and metaphors in addition to strict literal meaning. (e.g. we can understand what the phrase “how much did those shoes set you back?”). NLP is important in tagging, but even more important in the search process.
- Sentiment analysis – Tagging systems may be able to add some tags that describe sentiments. (e.g. It’s getting common for services to categorize facial expressions as being happy, sad or mad.) Some services may also be able to assign an emotion tag to images based upon subject matter, such as adding the keyword “sad” to a photo of a funeral.
- Situational analysis – One of he next great leaps in Computational Tagging will be true machine learning capability for situational analysis. Some of this is straightforward (e.g. “this is a soccer game”.) Some is more difficult (“This is a dangerous situation.”) At the moment, a lot of situational analysis is actually rule based. (e.g. Add the keyword vacation when you see a photo of a beach.)
- Celebrities – There is a big market of celebrity photos, and there are excellent training sets.
- Trademarks and products – Trademarks are also easy to identify, and there is a ready market for trademark identification (e.g. alert me whenever our trademark shows up in someone’s Instagram feed). When you get to specific products, you probably need to have a trainable system.
- Graphic elements – ML services can evaluate images according to nearly any graphic component. This includes shapes and colors in an image, These can be used to find similar images across a single collection or on the web at large. This was an early capability of rule-based AI service, and remains an important goal for both ML and DL services. .
- Aesthetic ranking – Computer vision can do some evaluation of image quality. It can find faces, blinks and smiles. It can also check for color, exposure and composition and make some programmatic ranking assessments.
- Image Matching services – Image matching as a technology is pretty mature, but the services built on image matching are just beginning. Used on the open web, for instance, image matching can tell you about the spread of an idea or meme. It can also help you find duplicate or similar images within your own system, company or library.
- Linked data – There is an unlimited body of knowledge about the people, places and events shown in an image collection – far more than could ever be stuffed in to a database. Linking media objects to data stacks will be a key tool to understanding the subject matter of the photo in a programmatic context.
- Data exhaust – I use this term to mean the personal data that you create as you move through the world, which could be used to help understand the meaning and context of an image. Your calendar entries, texts or emails all contain information that is useful for automatically tagging images. There are lots of difficult privacy issues related to this, but it’s the most promising way to attach knowledge specific to the creator to the object.
- Language Translation – We’re probably all familiar with the ability to use Google Translate to change a phrase from one language to another. Building language translation into image semantics will help to make it a truly transcultural communication system.